Introduction
This document describes all the features provided by the wordpredictor package. It first describes how to generate n-gram models. Next it describes how to evaluate the performance of the n-gram models. Finally it describes how to make word predictions using the n-gram model.
Environment setup code
The following code should be run before running the examples.
library(wordpredictor)
# The level of verbosity in the information messages
ve <- 0
#' @description
#' Used to setup the test environment
#' @param rf The required files.
#' @param ve The verbosity level.
#' @return The list of directories in the test environment
setup_env <- function(rf, ve) {
# An object of class EnvManager is created
em <- EnvManager$new(rp = "../", ve = ve)
# The required files are downloaded
ed <- em$setup_env(rf)
return(ed)
}
#' @description
#' Used to clean up the test environment
clean_up <- function(ve) {
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve)
# The test environment is removed
em$td_env(F)
}Model Generation
The wordpredictor package provides several classes that can be used to generate n-gram models. These classes may be used to generate n-gram models step by step. An alternative is to use the ModelGenerator class which combines all the steps and provides a single method for generating n-gram models.
The following steps are involved in generating n-gram models:
Data Exploration
The first step in generating a n-gram model is data exploration. This involves determining the type of textual content and various text related statistics. The type of text may be news content, blog posts, Twitter feeds, product reviews, customer chat history etc. Example of text related statistics are line count, word count, average line length and input file size.
It is also important to determine the unwanted words and symbols in the data such as vulgar words, punctuation symbols, non-alphabetical symbols etc. The wordpredictor package provides the DataAnalyzer class which can be used to find out statistics about the input data. The following example shows how to get statistics on all text files within a folder:
# The required files
rf <- c(
"test.txt",
"validate.txt",
"validate-clean.txt",
"test-clean.txt"
)
# The test environment is setup
ed <- setup_env(rf, ve)
# The DataAnalyzer object is created
da <- DataAnalyzer$new(ve = ve)
# Information on all text files in the ed folder is returned
fi <- da$get_file_info(ed)
# The file information is printed
print(fi)
#> $file_stats
#> fn total_lc max_ll min_ll mean_ll size
#> 1 /tmp/RtmpcFJ2MG/test-clean.txt 73 50 25 39 2.8 Kb
#> 2 /tmp/RtmpcFJ2MG/test.txt 73 51 28 41 3 Kb
#> 3 /tmp/RtmpcFJ2MG/validate-clean.txt 75 48 10 37 2.8 Kb
#> 4 /tmp/RtmpcFJ2MG/validate.txt 73 50 31 40 2.9 Kb
#>
#> $overall_stats
#> total_lc max_ll min_ll mean_ll total_s
#> 1 294 51 31 41 11.5 Kb
# The test environment is cleaned up
clean_up(ve)The word count of a text file can be fetched using the command:
cat file-name | wc -w. This command should work on all Unix
based systems.
Data Sampling
The next step is to generate training, testing and validation samples
from the input text file. If there are many input text files, then they
can be combined to a single file using the command:
cat file-1 file-2 file3 > output-file. The contents of
the combined text file may need to be randomized.
The wordpredictor package provides the DataSampler class which can be used to generate a random sample containing given number of lines. The following example shows how to generate a random sample of size 10 Mb from an input text file:
# The required files
rf <- c("input.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The sample size as a proportion of the input.txt file
ssize <- 0.1
# The data file path
dfp <- paste0(ed, "/input.txt")
# The object size is formatted
obj_size <- file.size(dfp) / 10^6
# The proportion of data to sample
prop <- (ssize / obj_size)
# An object of class DataSampler is created
ds <- DataSampler$new(dir = ed, ve = ve)
# The sample file is generated.
# The randomized sample is saved to the file train.txt in the ed folder
ds$generate_sample(
fn = "input.txt",
ss = prop,
ic = F,
ir = T,
ofn = "train.txt",
is = T
)
# The test environment is cleaned up
clean_up(ve)Usually we need a train data set for generating the n-gram model. A test data set for testing the model and a validation data set for evaluating the performance of the model. The following example shows how to generate the train, test and validation files. The train file contains the first 80% of the lines, the test set contains the next 10% of the lines. The remaining lines are in the validation set.
The data in the validation file must be different from the data in the train file. Otherwise it can result in over-fitting of the model. When a model is over-fitted, the model evaluation results will be exaggerated, overly optimistic and unreliable. So care should be taken to ensure that the data in the validation and train files is different.
# The required files
rf <- c("input.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# An object of class DataSampler is created
ds <- DataSampler$new(dir = ed, ve = ve)
# The train, test and validation files are generated
ds$generate_data(
fn = "input.txt",
percs = list(
"train" = 0.8,
"test" = 0.1,
"validate" = 0.1
)
)
# The test environment is cleaned up
clean_up(ve)In the above example, dir parameter is the directory containing the input.txt file and the generated test, validation and train data files.
Data Cleaning
The next step is to remove unwanted symbols and words from the input text file. This reduces the memory requirement of the n-gram model and makes it more efficient. Example of unwanted words are vulgar words, words that are not part of the vocabulary, punctuation, numbers, non-printable characters and extra spaces.
The wordpredictor package provides the DataCleaner class which can be used to remove unwanted words and symbols from text files. The following example shows how to clean a given text file:
# The required files
rf <- c("input.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The data file path
fn <- paste0(ed, "/input.txt")
# The clean file path
cfn <- paste0(ed, "/input-clean.txt")
# The data cleaning options
dc_opts <- list(
"min_words" = 2,
"to_lower" = T,
"remove_stop" = F,
"remove_punct" = T,
"remove_non_dict" = T,
"remove_non_alpha" = T,
"remove_extra_space" = T,
"remove_bad" = F,
"output_file" = cfn
)
# The data cleaner object is created
dc <- DataCleaner$new(fn, dc_opts, ve = ve)
# The sample file is cleaned and saved as input-clean.txt in the ed dir
dc$clean_file()
# The test environment is cleaned up
clean_up(ve)The clean_file method reads a certain number of lines at a time, cleans the lines of text and saves them to an output text file. It can be used for cleaning large text files.
Tokenization
The next step is to generate n-gram tokens from the cleaned text file. The TokenGenerator class allows generating n-gram tokens of given size from a given input text file. The following example shows how to generate n-grams tokens of size 1,2,3 and 4:
# The required files
rf <- c("test-clean.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The test file path
fn <- paste0(ed, "/test-clean.txt")
# The n-grams are generated
for (n in 1:4) {
# The ngram number is set
tg_opts <- list("n" = n, "save_ngrams" = T, dir = ed)
# The TokenGenerator object is created
tg <- TokenGenerator$new(fn, tg_opts, ve = ve)
# The ngram tokens are generated
tg$generate_tokens()
}
# The test environment is cleaned up
clean_up(ve)The above code generates the files n1.RDS, n2.RDS, n3.RDS and n4.RDS in the data directory. These files contains n-gram tokens along with their frequencies. N-grams of larger size provide more context. Usually n-grams of size 4 are generated.
Two important customization options supported by the TokenGenerator class are min_freq and stem_words. min_freq sets minimum frequency for n-gram tokens. All n-gram tokens with frequency less than min_freq are excluded.
The stem_words option is used to transform n-gram prefix components to their stems. The next word is not transformed.
The n-gram token frequencies may be analyzed using the DataAnalyzer class. The following example displays the top most occurring 2-gram tokens:
# The required files
rf <- c("n2.RDS")
# The test environment is setup
ed <- setup_env(rf, ve)
# The ngram file name
fn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(fn, ve = ve)
# The top features plot is checked
df <- da$plot_n_gram_stats(opts = list(
"type" = "top_features",
"n" = 10,
"save_to" = "png",
"dir" = "./reference/figures"
))
# The output file path
fn <- paste0("./reference/figures/top_features.png")
knitr::include_graphics(fn)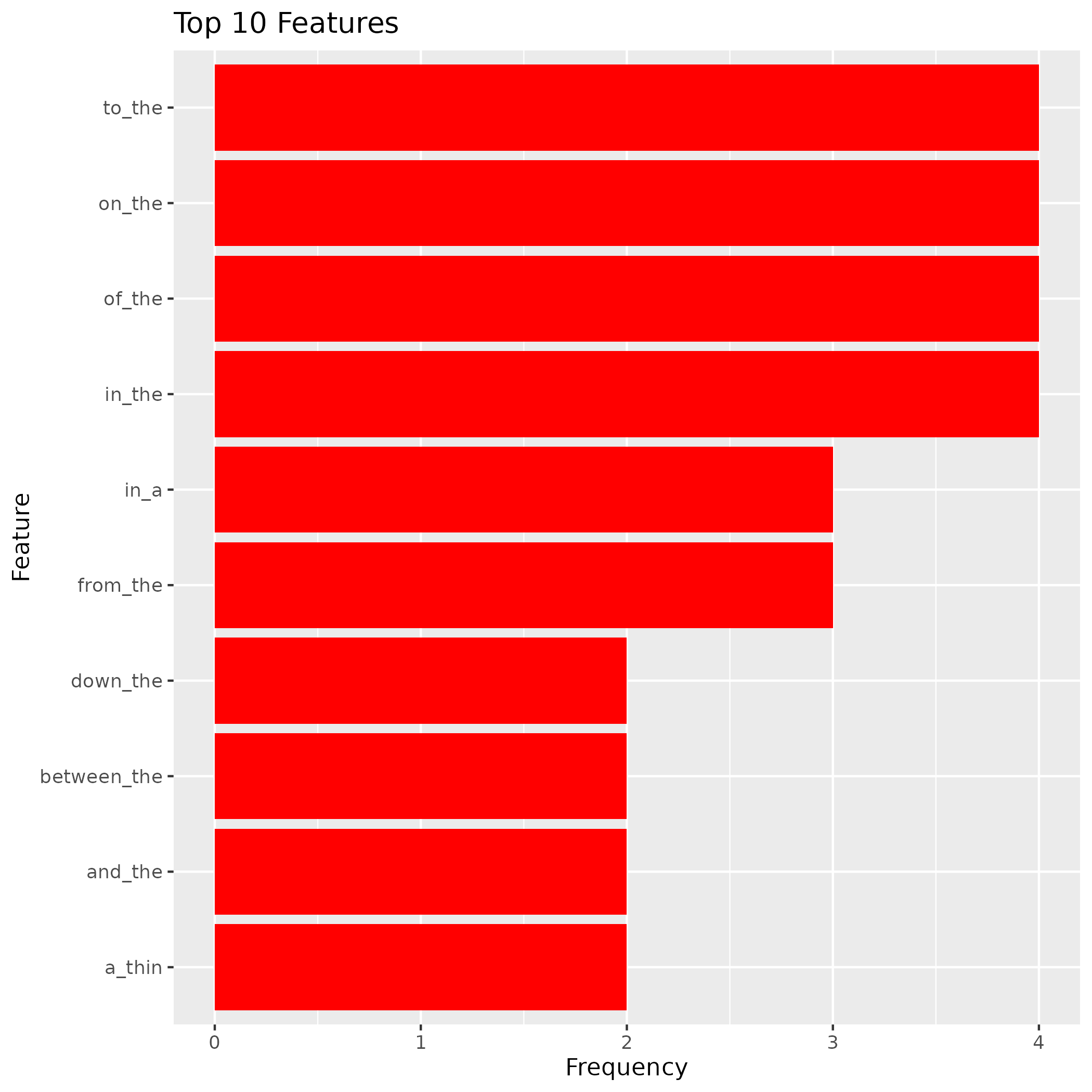
# The test environment is cleaned up
clean_up(ve)The following example shows the distribution of word frequencies:
# The required files
rf <- c("n2.RDS")
# The test environment is setup
ed <- setup_env(rf, ve)
# The ngram file name
fn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(fn, ve = ve)
# The top features plot is checked
df <- da$plot_n_gram_stats(opts = list(
"type" = "coverage",
"n" = 10,
"save_to" = "png",
"dir" = "./reference/figures"
))
# The output file path
fn <- paste0("./reference/figures/coverage.png")
knitr::include_graphics(fn)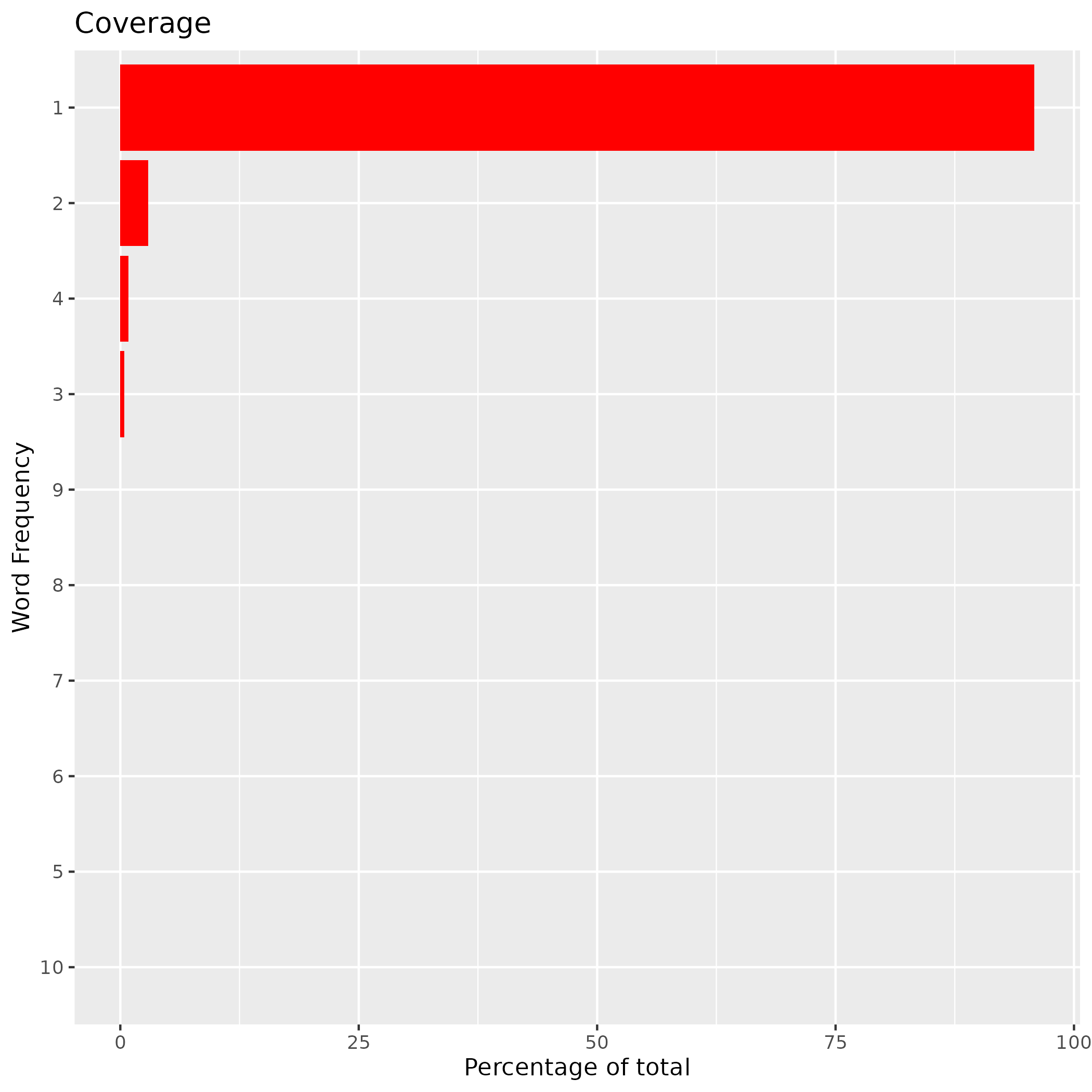
# The test environment is cleaned up
clean_up(ve)The following example returns top 10 2-gram tokens that start with and_:
# The required files
rf <- c("n2.RDS")
# The test environment is setup
ed <- setup_env(rf, ve)
# The ngram file name
fn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(ve = ve)
# Bi-grams starting with "and_" are returned
df <- da$get_ngrams(fn = fn, c = 10, pre = "^and_*")
# The data frame is sorted by frequency
df <- df[order(df$freq, decreasing = T), ]
# The first 10 rows of the data frame are printed
knitr::kable(df[1:10, ], col.names = c("Prefix", "Frequency"))| Prefix | Frequency |
|---|---|
| and_the | 2 |
| and_cart | 1 |
| and_fired | 1 |
| and_forget | 1 |
| and_leave | 1 |
| and_open | 1 |
| and_out | 1 |
| and_phrase | 1 |
| and_say | 1 |
| and_tea | 1 |
# The test environment is cleaned up
clean_up(ve)Transition Probabilities
The next step in generating the n-gram model is to generate transition probabilities (tp) from the n-gram files. The TPGenerator class is used to generate the tps. For each n-gram token file a corresponding tp file is generated.
The tp files are then combined into a single file containing tp data for n-grams of size 1, 2, 3, 4 etc.
The following example shows how to generate combined tps for n-grams of size 1, 2, 3 and 4:
# The required files
rf <- c("n1.RDS", "n2.RDS", "n3.RDS", "n4.RDS")
# The test environment is setup
ed <- setup_env(rf, ve)
# The TPGenerator object is created
tp <- TPGenerator$new(opts = list(n = 4, dir = ed), ve = ve)
# The combined transition probabilities are generated
tp$generate_tp()
# The test environment is cleaned up
clean_up(ve)The above code produces the file model-4.RDS.
The model file
The final step is to generate a n-gram model file from the files generated in the previous steps. The Model class contains the method load_model, which reads the combined tps files and other files that are used by the model. An instance of the Model class represents the n-gram model.
Generating the model in one step
All the previous steps may be combined into a single step. The ModelGenerator class allows generating the final n-gram model using a single method call. The following example generates a n-gram model using default data cleaning and tokenization options:
# The required files
rf <- c("input.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The following code generates n-gram model using default options for data
# cleaning and tokenization. See the following section on how to customize these
# options. Note that input.txt is the name of the input data file. It should be
# present in the data directory. dir is the directory containing the input and
# output files. It is set to the path of the environment directory, ed.
# ModelGenerator class object is created
mg <- ModelGenerator$new(
name = "def-model",
desc = "N-gram model generating using default options",
fn = "def-model.RDS",
df = "input.txt",
n = 4,
ssize = 0.1,
dir = ed,
dc_opts = list(),
tg_opts = list(),
ve = ve
)
# Generates n-gram model. The output is the file def-model.RDS
mg$generate_model()
# The test environment is cleaned up
clean_up(ve)Evaluating the model performance
The wordpredictor package provides the ModelEvaluator class for evaluating the performance of the generated n-gram model. Intrinsic and Extrinsic evaluation are supported. Also the performance of several n-gram models may be compared.
The following example performs Intrinsic evaluation. It measures the Perplexity score for each sentence in the validation.txt file, that was generated in the data sampling step. It returns the minimum, mean and maximum Perplexity score for each line.
# The required files
rf <- c("def-model.RDS", "validate-clean.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The model file name
mfn <- paste0(ed, "/def-model.RDS")
# The path to the cleaned validation file
vfn <- paste0(ed, "/validate-clean.txt")
# ModelEvaluator class object is created
me <- ModelEvaluator$new(mf = mfn, ve = ve)
# The intrinsic evaluation is performed on first 20 lines
stats <- me$intrinsic_evaluation(lc = 20, fn = vfn)
# The test environment is cleaned up
clean_up(ve)The following example performs Extrinsic evaluation. It measures the accuracy score for each sentence in validation.txt file. For each sentence the model is used to predict the last word in the sentence given the previous words. If the last word was correctly predicted, then the prediction is considered to be accurate.
# The required files
rf <- c("def-model.RDS", "validate-clean.txt")
# The test environment is setup
ed <- setup_env(rf, ve)
# The model file name
mfn <- paste0(ed, "/def-model.RDS")
# The path to the cleaned validation file
vfn <- paste0(ed, "/validate-clean.txt")
# ModelEvaluator class object is created
me <- ModelEvaluator$new(mf = mfn, ve = ve)
# The intrinsic evaluation is performed on first 100 lines
stats <- me$extrinsic_evaluation(lc = 100, fn = vfn)
# The test environment is cleaned up
clean_up(ve)Making word predictions
The n-gram model generated in the previous step can be used to predict the next word given a set of words. The following example shows how to predict the next word. It returns the 3 possible next words along with their probabilities.
# The required files
rf <- c("def-model.RDS")
# The test environment is setup
ed <- setup_env(rf, ve)
# The model file name
mfn <- paste0(ed, "/def-model.RDS")
# An object of class ModelPredictor is created. The mf parameter is the name of
# the model file that was generated in the previous example.
mp <- ModelPredictor$new(mf = mfn, ve = ve)
# Given the words: "how are", the next word is predicted. The top 3 most likely
# next words are returned along with their respective probabilities.
res <- mp$predict_word(words = "how are", 3)
# The test environment is cleaned up
clean_up(ve)