It provides a method that returns information about text files, such as number of lines and number of words. It also provides a method that displays bar plots of n-gram frequencies. Additionally it provides a method for searching for n-grams in a n-gram token file. This file is generated using the TokenGenerator class.
Details
It provides a method that returns text file information. The text file information includes total number of lines, max, min and mean line length and file size.
It also provides a method that generates a bar plot showing the most common n-gram tokens.
Another method is provided which returns a list of n-grams that match the given regular expression.
Super class
wordpredictor::Base -> DataAnalyzer
Methods
Method new()
It initializes the current object. It is used to set the file name and verbose options.
Usage
DataAnalyzer$new(fn = NULL, ve = 0)Method plot_n_gram_stats()
It allows generating two type of n-gram plots. It first reads n-gram token frequencies from an input text file. The n-gram frequencies are displayed in a bar plot.
The type of plot is specified by the type option. The type options can have the values 'top_features' or 'coverage'. 'top_features' displays the top n most occurring tokens along with their frequencies. 'coverage' displays the number of words along with their frequencies.
The plot stats are returned as a data frame.
Arguments
optsThe options for analyzing the data.
type. The type of plot to display. The options are: 'top_features', 'coverage'.
n. For 'top_features', it is the number of top most occurring tokens. For 'coverage' it is the first n frequencies.
save_to. The graphics devices to save the plot to. NULL implies plot is printed.
dir. The output directory where the plot will be saved.
Examples
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL value implies tempdir will
# be used.
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("n2.RDS")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The n-gram file name
nfn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(nfn, ve = ve)
# The top features plot is checked
df <- da$plot_n_gram_stats(opts = list(
"type" = "top_features",
"n" = 10,
"save_to" = NULL,
"dir" = ed
))
# N-gram statistics are displayed
print(df)
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()Method get_file_info()
It generates information about text files. It takes as input a file or a directory containing text files. For each file it calculates the total number of lines, maximum, minimum and mean line lengths and the total file size. The file information is returned as a data frame.
Examples
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("test.txt")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The test file name
cfn <- paste0(ed, "/test.txt")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(ve = ve)
# The file info is fetched
fi <- da$get_file_info(cfn)
# The file information is printed
print(fi)
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()Method get_ngrams()
It extracts a given number of n-grams and their frequencies from a n-gram token file.
The prefix parameter specifies the regular expression for matching n-grams. If this parameter is not specified then the given number of n-grams are randomly chosen.
Arguments
fnThe n-gram file name.
cThe number of n-grams to return.
preThe n-gram prefix, given as a regular expression.
Examples
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("n2.RDS")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The n-gram file name
nfn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(nfn, ve = ve)
# Bi-grams starting with "and_" are returned
df <- da$get_ngrams(fn = nfn, c = 10, pre = "^and_*")
# The data frame is sorted by frequency
df <- df[order(df$freq, decreasing = TRUE),]
# The data frame is printed
print(df)
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()Examples
## ------------------------------------------------
## Method `DataAnalyzer$plot_n_gram_stats`
## ------------------------------------------------
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL value implies tempdir will
# be used.
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("n2.RDS")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The n-gram file name
nfn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(nfn, ve = ve)
# The top features plot is checked
df <- da$plot_n_gram_stats(opts = list(
"type" = "top_features",
"n" = 10,
"save_to" = NULL,
"dir" = ed
))
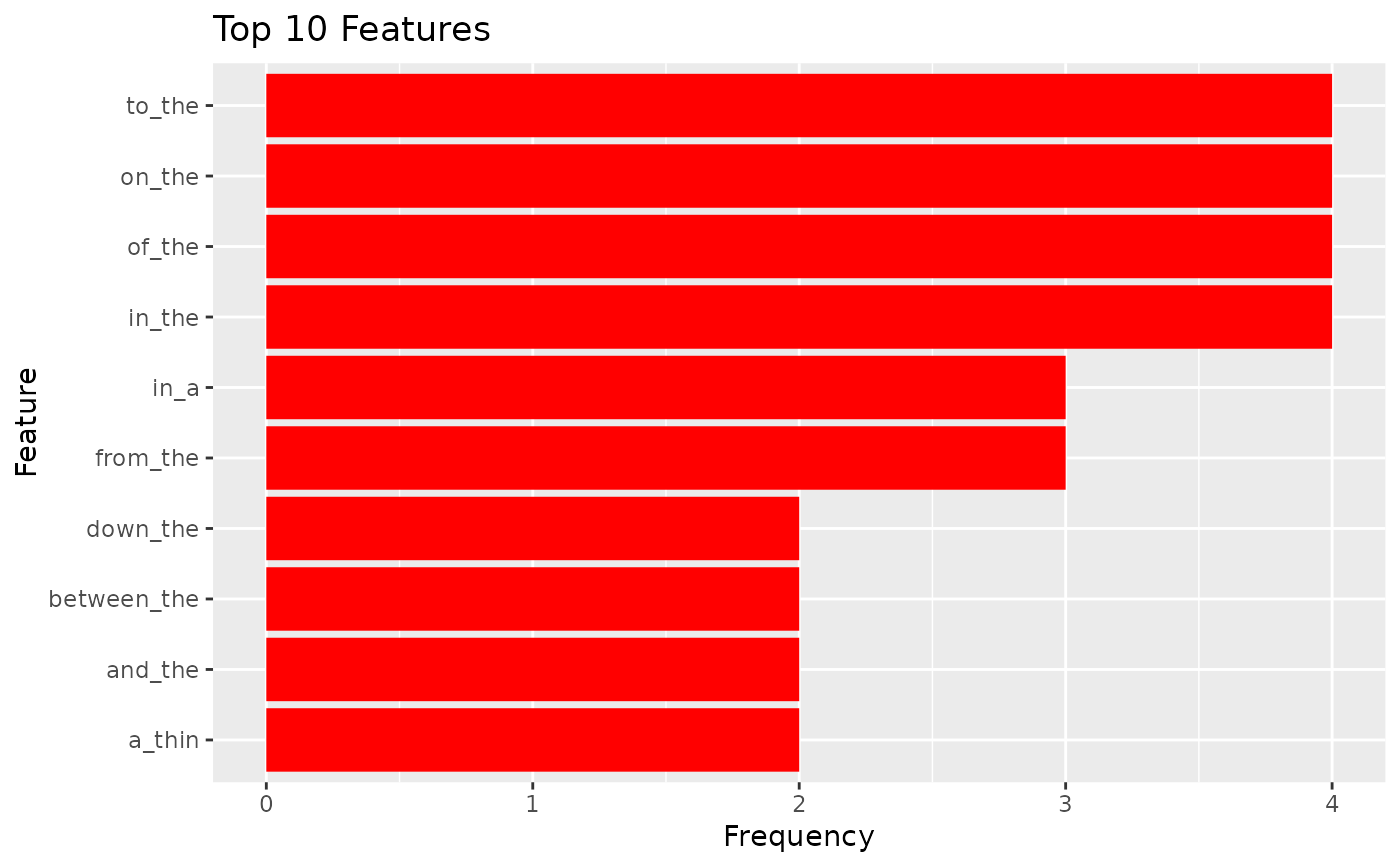 # N-gram statistics are displayed
print(df)
#> # A tibble: 10 × 2
#> pre freq
#> <chr> <dbl>
#> 1 in_the 4
#> 2 of_the 4
#> 3 on_the 4
#> 4 to_the 4
#> 5 from_the 3
#> 6 in_a 3
#> 7 a_thin 2
#> 8 and_the 2
#> 9 between_the 2
#> 10 down_the 2
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()
## ------------------------------------------------
## Method `DataAnalyzer$get_file_info`
## ------------------------------------------------
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("test.txt")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The test file name
cfn <- paste0(ed, "/test.txt")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(ve = ve)
# The file info is fetched
fi <- da$get_file_info(cfn)
# The file information is printed
print(fi)
#> $file_stats
#> fn total_lc max_ll min_ll mean_ll size
#> 1 /tmp/RtmpnAA6yo/test.txt 73 51 28 41 3 Kb
#>
#> $overall_stats
#> total_lc max_ll min_ll mean_ll total_s
#> 1 73 51 28 41 3 Kb
#>
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()
## ------------------------------------------------
## Method `DataAnalyzer$get_ngrams`
## ------------------------------------------------
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("n2.RDS")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The n-gram file name
nfn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(nfn, ve = ve)
# Bi-grams starting with "and_" are returned
df <- da$get_ngrams(fn = nfn, c = 10, pre = "^and_*")
# The data frame is sorted by frequency
df <- df[order(df$freq, decreasing = TRUE),]
# The data frame is printed
print(df)
#> # A tibble: 15 × 2
#> pre freq
#> <fct> <dbl>
#> 1 and_the 2
#> 2 and_cart 1
#> 3 and_fired 1
#> 4 and_forget 1
#> 5 and_leave 1
#> 6 and_open 1
#> 7 and_out 1
#> 8 and_phrase 1
#> 9 and_say 1
#> 10 and_tea 1
#> 11 and_tell 1
#> 12 and_then 1
#> 13 and_threw 1
#> 14 and_was 1
#> 15 and_watch 1
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()
# N-gram statistics are displayed
print(df)
#> # A tibble: 10 × 2
#> pre freq
#> <chr> <dbl>
#> 1 in_the 4
#> 2 of_the 4
#> 3 on_the 4
#> 4 to_the 4
#> 5 from_the 3
#> 6 in_a 3
#> 7 a_thin 2
#> 8 and_the 2
#> 9 between_the 2
#> 10 down_the 2
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()
## ------------------------------------------------
## Method `DataAnalyzer$get_file_info`
## ------------------------------------------------
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("test.txt")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The test file name
cfn <- paste0(ed, "/test.txt")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(ve = ve)
# The file info is fetched
fi <- da$get_file_info(cfn)
# The file information is printed
print(fi)
#> $file_stats
#> fn total_lc max_ll min_ll mean_ll size
#> 1 /tmp/RtmpnAA6yo/test.txt 73 51 28 41 3 Kb
#>
#> $overall_stats
#> total_lc max_ll min_ll mean_ll total_s
#> 1 73 51 28 41 3 Kb
#>
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()
## ------------------------------------------------
## Method `DataAnalyzer$get_ngrams`
## ------------------------------------------------
# Start of environment setup code
# The level of detail in the information messages
ve <- 0
# The name of the folder that will contain all the files. It will be
# created in the current directory. NULL implies tempdir will be used
fn <- NULL
# The required files. They are default files that are part of the
# package
rf <- c("n2.RDS")
# An object of class EnvManager is created
em <- EnvManager$new(ve = ve, rp = "./")
# The required files are downloaded
ed <- em$setup_env(rf, fn)
# End of environment setup code
# The n-gram file name
nfn <- paste0(ed, "/n2.RDS")
# The DataAnalyzer object is created
da <- DataAnalyzer$new(nfn, ve = ve)
# Bi-grams starting with "and_" are returned
df <- da$get_ngrams(fn = nfn, c = 10, pre = "^and_*")
# The data frame is sorted by frequency
df <- df[order(df$freq, decreasing = TRUE),]
# The data frame is printed
print(df)
#> # A tibble: 15 × 2
#> pre freq
#> <fct> <dbl>
#> 1 and_the 2
#> 2 and_cart 1
#> 3 and_fired 1
#> 4 and_forget 1
#> 5 and_leave 1
#> 6 and_open 1
#> 7 and_out 1
#> 8 and_phrase 1
#> 9 and_say 1
#> 10 and_tea 1
#> 11 and_tell 1
#> 12 and_then 1
#> 13 and_threw 1
#> 14 and_was 1
#> 15 and_watch 1
# The test environment is removed. Comment the below line, so the
# files generated by the function can be viewed
em$td_env()